I went looking for sustained-load benchmarks comparing MoE and Dense coding models on consumer GPUs. Not demo bursts on a Mac Mini — sustained autoregressive generation on real coding tasks, where architecture and interconnect are the only variables.
I found plenty of one-shot numbers. Nobody had published the comparison that matters: same hardware, same quantization, same inference engine, MoE versus Dense, across GPU configurations. Methodology visible. Numbers verifiable.
So I ran the tests. Dual RTX 3090s with NVLink, custom liquid cooling, a 6 kW isolation transformer feeding a double-conversion UPS. Not elegant, but thermally and electrically honest — sustained inference loads without throttling, no measurement fiction. The hardware details are below.
Scope: Inference-only. Autoregressive token generation for coding agents. Training workloads where interconnect bandwidth dominates gradient synchronization are a different discipline entirely. Code quality, tool-calling reliability, orchestrator compatibility — those dimensions matter too, but this piece measures one thing with discipline. The rest follows.
This is Part 1 of the Local LLM Bench series. Part 2 tests what happens when four agents hit the same GPU simultaneously. Part 3 scales to eight.
What You Should Build
| If you have… | MoE tok/s | Dense tok/s | Recommendation |
|---|---|---|---|
| 1x RTX 3090 | 168 | 41 | MoE. No contest. |
| 2x RTX 3090 (no NVLink) | 164 | 64 | MoE for speed. Dense only if you need its quality edge. |
| 2x RTX 3090 (NVLink) | 170 | 65 | NVLink adds <4%. Save the money. |
One used RTX 3090 (~$800), AWQ-4bit MoE at TP=1: 168 tok/s with 32K context. Enough for most coding agent tasks. Best performance-per-dollar for local inference. Need context beyond 32K? Add a second GPU over plain PCIe — skip NVLink.
Now, the data behind those numbers.
Why This Matters: Local Coding Agent Swarms
The emerging pattern is orchestrator + swarm: a powerful model (Claude Opus, GPT) plans and decomposes work, then delegates parallelizable tasks to faster, cheaper models. Code generation, test writing, refactoring, documentation — embarrassingly parallel.
Running those swarm agents locally gives you cost (zero API spend for bulk generation), latency (no network round-trip, sub-second time-to-first-token), and privacy (code never leaves your machine). There’s a fourth advantage that isn’t obvious from the numbers: data sovereignty. Frontier models handle reasoning and orchestration; the local model handles execution. Your proprietary code and business data stay on your network. The frontier model sees task descriptions and reviews outputs; the local model sees the actual codebase. That boundary only gets more relevant as data residency requirements tighten.
For this to be practical, the local model needs >100 tok/s for interactive agent loops, native tool calling, good code quality, and affordable hardware — ideally a single consumer GPU. As the results show, MoE models hit all four on an $800 used RTX 3090.
The Models
| MoE | Dense | |
|---|---|---|
| Model | Qwen3-Coder-30B-A3B-Instruct | Qwen2.5-Coder-32B-Instruct |
| Architecture | Mixture-of-Experts | Dense transformer |
| Total parameters | 30.5B | 32.5B |
| Active parameters/token | 3.3B (8 of 128 experts) | 32.5B (all weights) |
| Quantization | AWQ 4-bit (Marlin kernels) | AWQ 4-bit (Marlin kernels) |
| Model size on disk | 16.9 GB | 19.5 GB |
| Context | 256K native | 128K (configured at 32K for VRAM) |
| Native tool calling | Yes | No |
| Designed for | Agentic coding, SWE-bench, terminal-bench | General coding |
Both use identical Marlin AWQ kernels on Ampere Tensor Cores. The only variable is architecture.
Qwen3-Coder is one generation newer than Qwen2.5-Coder — intentional. These are the best available coding models in each architecture class. The comparison answers which model should I run? not the theoretical is MoE faster at equal quality? Some portion of the throughput gap reflects Qwen3’s architectural optimizations beyond MoE alone.
The Hardware
| Component | Spec |
|---|---|
| GPUs | 2x NVIDIA RTX 3090 24GB (Ampere, SM 8.6) |
| Interconnect | NV3 NVLink (3 lanes, ~112 GB/s bidirectional) |
| PCIe | Gen 4.0 x16 (~25 GB/s per GPU) |
| CPU | AMD Threadripper (Gigabyte TRX40 Aorus Master) |
| RAM | 64GB DDR4 |
| Storage | PM1735 enterprise NVMe (5.4TB ZFS pool) |
| Cooling | Custom loop, waterblocked GPUs, 360mm radiator |
| Power | 6 kW UPS, 6 kW transformer (wye phase+neutral) |
| OS | Ubuntu 24.04, CUDA 12.8, driver 570.133.20 |
The Benchmark
Five coding tasks — the kind agents actually do:
| Prompt | Task Type | What It Tests |
|---|---|---|
| Implement LRU Cache | Algorithm implementation | Data structure design, O(1) complexity, type hints |
| Debug Merge Sort | Bug finding & fixing | Code comprehension, error analysis, corrected output |
| Pytest Suite | Test generation | Parametrize, edge cases, 12+ test cases for a cron parser |
| Refactor Flask Route | Architecture refactoring | Service layer, repository pattern, separation of concerns |
| Rate Limiter Design | System design + implementation | Token bucket, thread safety, decorator pattern |
Methodology: Each prompt at max_tokens=4096, temperature=0.7. Thinking mode disabled. Served via vLLM’s OpenAI-compatible chat completions API. Two runs per config (warmup then measurement). Tokens/second = API-reported completion_tokens / wall-clock time. All responses completed naturally except one test-generation prompt that hit the 4096-token cap. vLLM 0.17.0rc1 with --enable-chunked-prefill, --max-num-seqs 4, --gpu-memory-utilization 0.92.
Configurations: (1) TP=2, NVLink — both GPUs, NVLink active. (2) TP=1, Single GPU — one GPU only. (3) TP=2, PCIe only — both GPUs, NVLink disabled via NCCL_P2P_DISABLE=1.
Results
Note on “Max Context”: Maximum supported context lengths at each configuration given available VRAM — not the context length used during testing.
MoE: Qwen3-Coder-30B-A3B AWQ-4bit (3.3B active)
| Configuration | Impl | Debug | Test | Refactor | Design | Average | Max Context |
|---|---|---|---|---|---|---|---|
| TP=2, NVLink | 170.0 | 167.3 | 169.6 | 168.5 | 170.7 | 169.7 tok/s | 131K |
| TP=1, Single GPU | 169.2 | 168.8 | 168.0 | 168.1 | 168.5 | 168.4 tok/s | 32K |
| TP=2, PCIe only | 165.9 | 162.9 | 163.2 | 160.7 | 164.5 | 163.5 tok/s | 131K |
Dense: Qwen2.5-Coder-32B AWQ-4bit (32B active)
| Configuration | Impl | Debug | Test | Refactor | Design | Average | Max Context |
|---|---|---|---|---|---|---|---|
| TP=2, NVLink | 65.6 | 65.1 | 65.5 | 64.9 | 65.6 | 65.4 tok/s | 32K |
| TP=1, Single GPU | 41.0 | 40.9 | 40.9 | 41.0 | 41.0 | 41.0 tok/s | 8K |
| TP=2, PCIe only | 63.9 | 63.5 | 63.7 | 63.4 | 63.8 | 63.7 tok/s | 32K |
Head-to-Head
| Configuration | MoE | Dense | MoE Advantage |
|---|---|---|---|
| TP=2 NVLink | 169.7 | 65.4 | 2.6x |
| TP=1 Single GPU | 168.4 | 41.0 | 4.1x |
| TP=2 PCIe only | 163.5 | 63.7 | 2.6x |
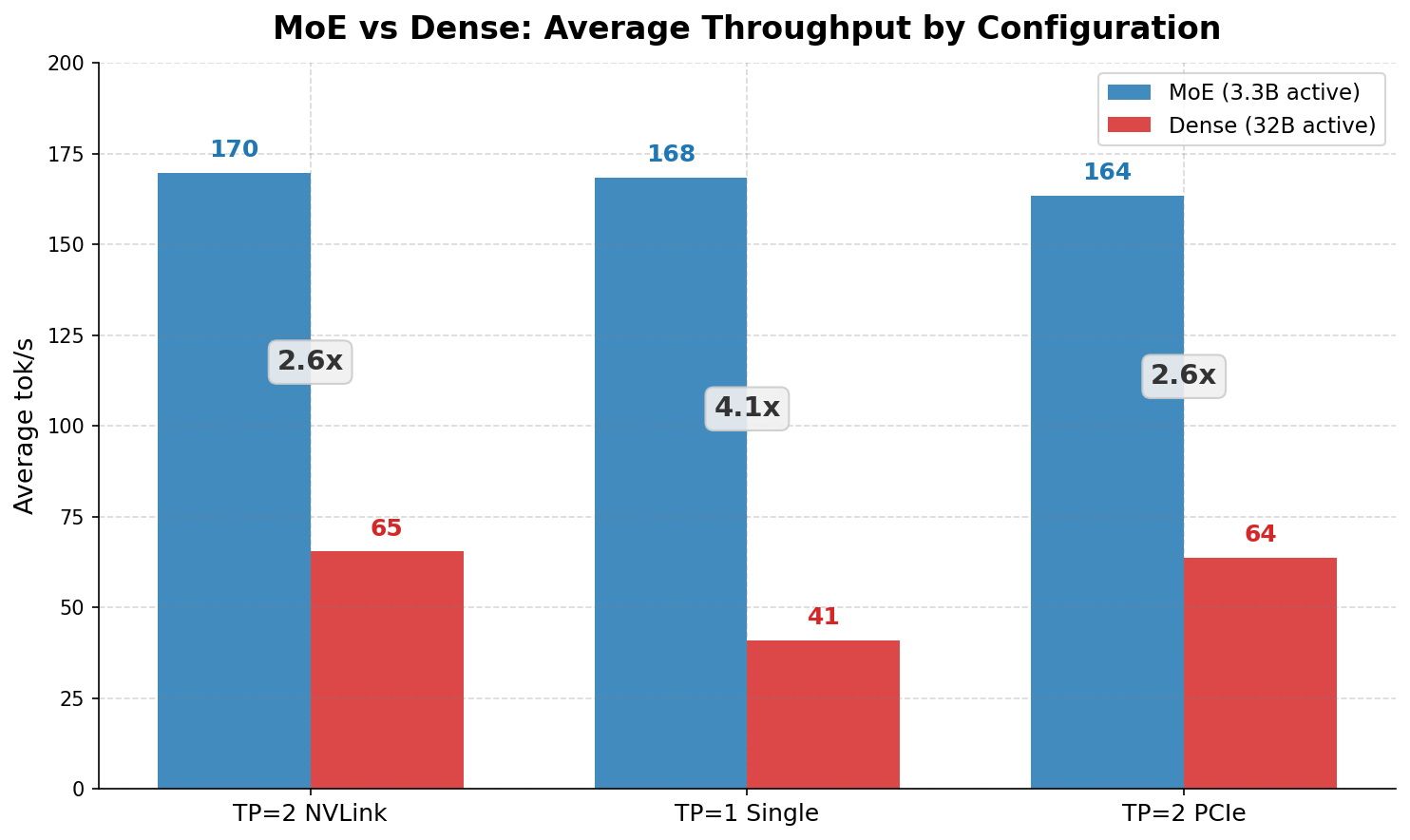
Analysis
MoE doesn’t care about your GPU topology. The MoE model delivers 164–170 tok/s regardless of configuration. Single GPU, dual GPU, NVLink, PCIe — spread is 3.8%. It activates 3.3B parameters per token; one RTX 3090’s 936 GB/s memory bandwidth serves that without breaking a sweat. The only reason to add a second GPU is context length: one 24GB GPU fits the 17GB model plus ~7GB KV cache (~32K context). Two GPUs give you 131K.
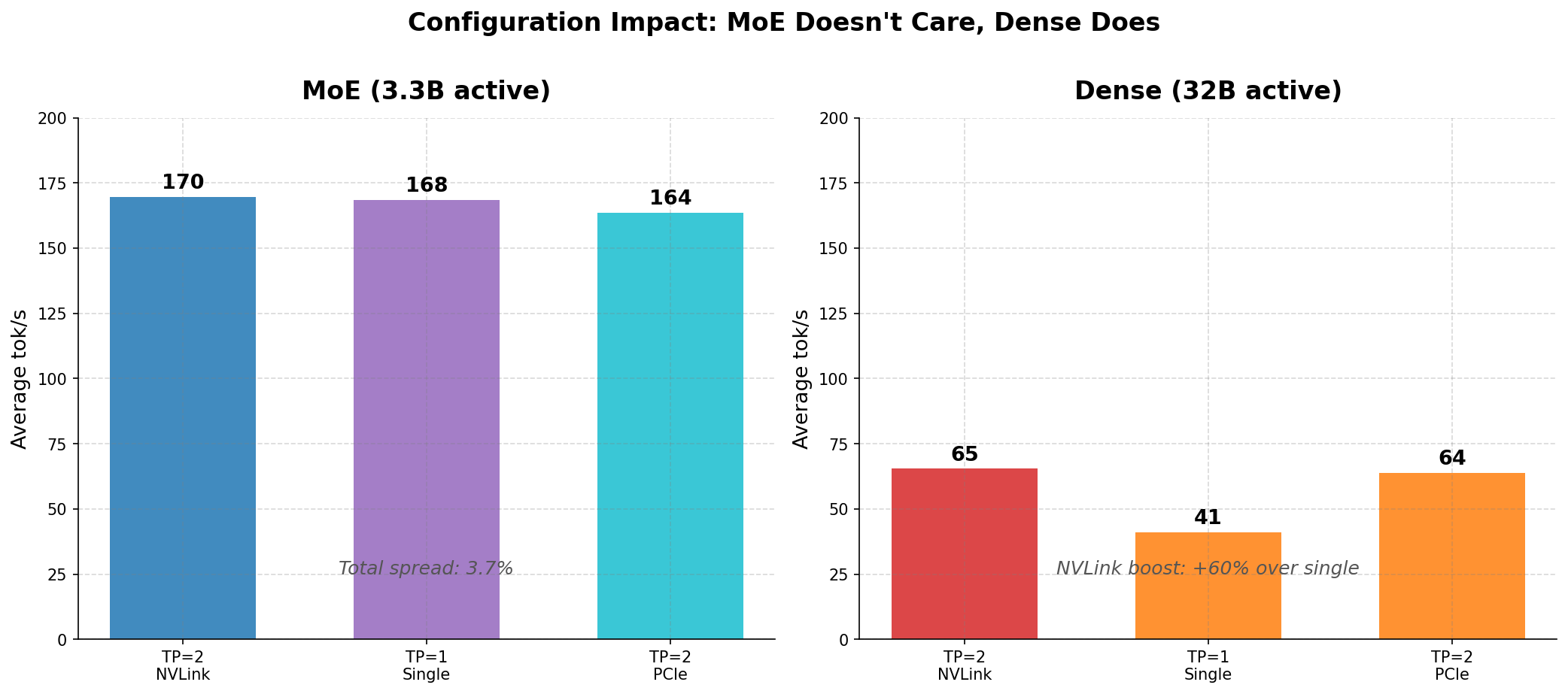
Dense needs two GPUs — but NVLink barely matters. Going from one GPU to two with NVLink gives a 59% throughput boost (41 → 65 tok/s). PCIe-only dual GPU (63.7 tok/s) comes within 2.7% of NVLink (65.4 tok/s). At single-request batch size, the all-reduce payload is small enough that PCIe Gen 4 handles it. NVLink’s advantage grows at higher concurrency — we measure that in Part 2.
Single GPU is where MoE dominates. One RTX 3090: MoE at 168 tok/s, dense at 41 tok/s — 4.1x. At 168 tok/s, a 1000-token function completes in ~6 seconds. At 41 tok/s, the same task takes 24 seconds — too slow for interactive agent loops.
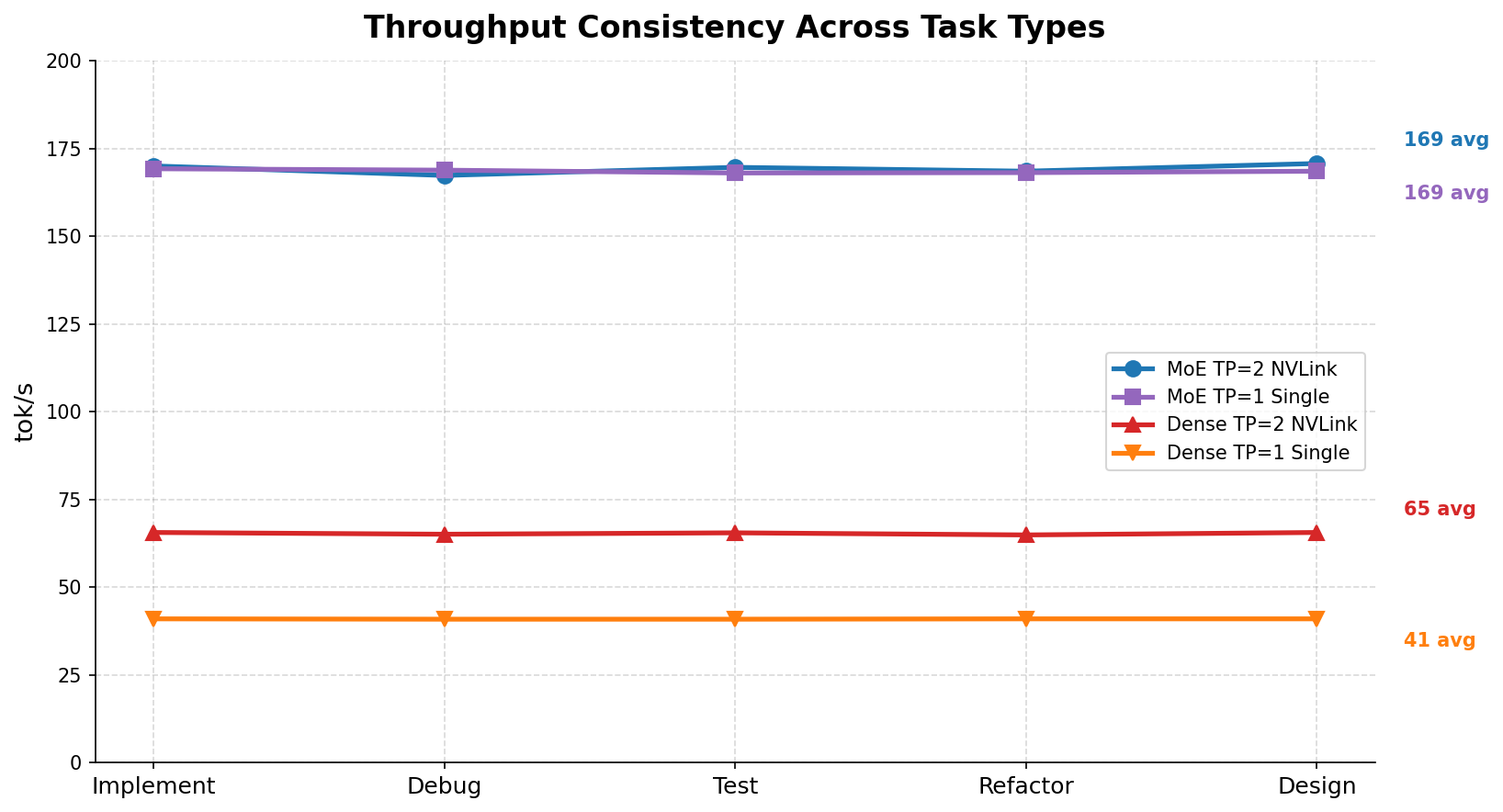
Throughput is consistent across task types. Both models show near-flat throughput regardless of prompt complexity. You can reliably predict completion times for agent task scheduling.
A Note on Thinking Mode
Both models were benchmarked with thinking mode disabled. Qwen3-Coder supports an optional thinking mode (<think>...</think> reasoning tokens) that may improve code quality at the cost of effective throughput. The numbers above are raw generation speed; with thinking enabled, a portion of tokens are internal reasoning the agent doesn’t use. That trade-off is for a follow-up benchmark.
Why AWQ 4-bit, Not FP8?
The RTX 3090 (Ampere, SM 8.6) has Tensor Cores for FP16, BF16, INT8, and INT4. Native FP8 was introduced in Ada Lovelace and Hopper. On a 3090, FP8 models are decompressed to FP16 on the fly — a compute tax. Our earlier testing showed FP8 13% slower than AWQ 4-bit on the same MoE model. AWQ 4-bit with Marlin is mature on Ampere: smaller files (17GB vs 30GB), more VRAM for KV cache, higher throughput. Quality impact is negligible (~0.7% perplexity). On Ada/Hopper, native FP8 would change the calculus; we haven’t measured that.
The Agent Architecture
At 168 tok/s, a 500-token code generation completes in ~3 seconds. Three parallel subagents can each produce a complete file in the time it takes to review the output. The orchestrator (Claude Code) handles planning, architectural reasoning, and quality review; the local swarm handles volume — boilerplate, test scaffolding, documentation, single-function implementations. Faster iteration, lower cost.
What to Build
One GPU, ~$800: the sweet spot. Used RTX 3090, AWQ-4bit MoE at TP=1. Best performance-per-dollar; 32K context is enough for most agent tasks.
Two GPUs, ~$1600: only if you need long context. Skip NVLink. Two RTX 3090s over PCIe deliver 164 tok/s with 131K context. The 4% NVLink speedup doesn’t justify bridges and compatible motherboards.
Quantization: AWQ-4bit wins on Ampere. Faster than FP8, smaller on disk, quality loss negligible. FP8 makes sense on GPUs with native FP8 compute — not here.
Dense models still have their place. If you need the best code quality and have two GPUs, a dense 32B at 65 tok/s is viable for non-interactive workloads — background batch generation, overnight code review. For interactive agent loops, MoE wins.
The Stack
| Component | What | Why |
|---|---|---|
| vLLM 0.17.0 nightly | Inference engine | Required for Qwen3 MoE support |
--disable-custom-all-reduce | vLLM flag | Custom all-reduce crashes on SM 8.6 (RTX 3090) |
--tool-call-parser qwen3_coder | vLLM flag | Enables native tool calling for agent workflows |
NCCL_P2P_DISABLE=1 | Environment variable | Forces PCIe transport (for benchmarking or non-NVLink systems) |
| LiteLLM | API proxy | Translates Anthropic API to OpenAI API for Claude Code integration |
This benchmark uses vLLM 0.17.0rc1 nightly (Qwen3 MoE). Qwen3.5 MoE (e.g. Qwen3.5-35B-A3B) uses a different architecture not yet available in this build.
What Comes Next
These are single-request numbers. One prompt in, one response out. Clean, isolated, reproducible.
That’s not how swarms work. An orchestrator dispatches four tasks simultaneously. The local model serves all four. Memory bandwidth contends. Per-task throughput drops. The question isn’t whether it drops — it’s whether MoE’s bandwidth headroom absorbs the penalty better than Dense.
Part 2 of this series answers that. The short version: the advantage gets wider under load, not narrower. One GPU, four agents, 336 effective tok/s. The numbers change the recommendation from “MoE is faster” to “MoE is the only architecture that makes local swarms practical on consumer hardware.”
Benchmarked March 6, 2026. Hardware: 2x NVIDIA RTX 3090 24GB, NV3 NVLink, AMD Threadripper, 64GB RAM, PM1735 NVMe. Software: vLLM 0.17.0rc1, Ubuntu 24.04, CUDA 12.8, driver 570.133.20. All benchmark code, raw CSV data, and chart generation scripts at github.com/sch0tten/local-llm-eval.