A three-billion-parameter vision model looked at a reCAPTCHA tile and got it right 89 percent of the time. It took 128 milliseconds.
A lookup over a few hundred megabytes got it right 95 percent of the time. It took seven-tenths of a millisecond.
Same tiles. Same held-out set. One of those is how almost everyone is wiring computer vision into their stack this year. The other is how you should.
The fast one was not a smaller model. It was not a model at all. It was retrieval.
I have spent the last stretch building a visual RAG corpus and measuring it head to head against the obvious alternative: point a modern vision-language model at the problem and let it reason its way to an answer. The vision model is the default reach. It is also the slow path, the expensive path, and the path that forgets everything it just figured out the moment the context window closes. This is the case against that reach, written in measurements.
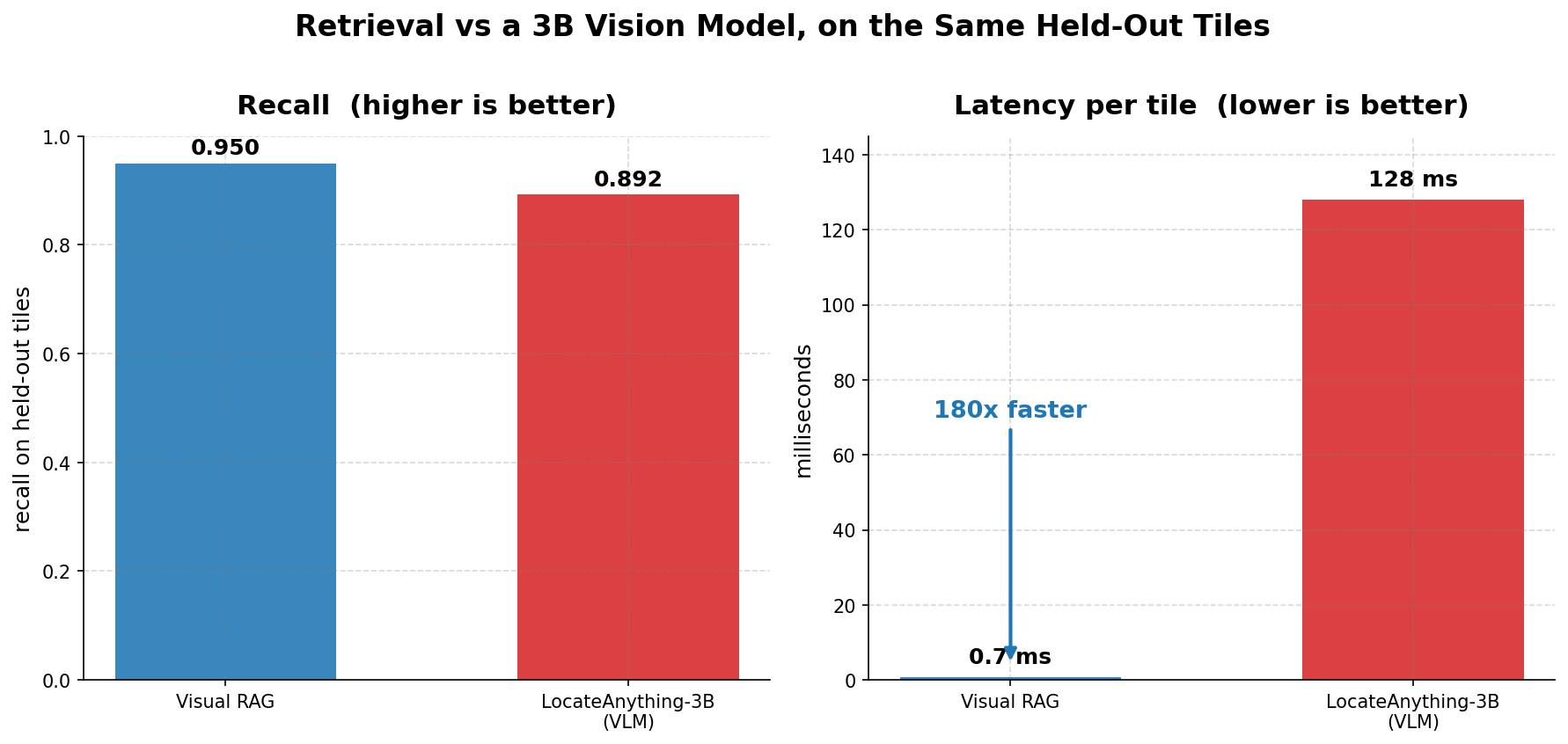
Same tiles, same held-out set. Retrieval wins on accuracy and finishes 180 times sooner. That 0.7 ms bar on the right is the sliver you can barely see.
And before the obvious objection writes itself: yes, this system knows sixteen categories, not the open world a frontier model will take a swing at. That is not a limitation I am tucking into a footnote. The narrow scope is the whole point of the exercise, and I make the full case for it further down. A small problem solved completely, cheaply, and for keeps beats a vast one solved expensively and never quite finished.
The anvil, not the product
I needed the hardest visual recognition problem I could get my hands on. Not a friendly one. Not “is this a golden retriever.” I wanted images that were engineered, on purpose, by people with budgets, to break automated vision.
So I used reCAPTCHA tiles. The little grids of crosswalks and fire hydrants and buses that stand between you and the rest of the internet a dozen times a week. They are arguably the most-seen images on Earth, and every one of them is adversarial by design. The whole point of that dataset is to be solvable by a human and miserable for a machine. If a method holds up against the worst the gatekeepers can throw at it, it will hold up against your warehouse camera, your triage queue, your document backlog.
One thing up front, and I mean it. This study is not reproducible, by design. I am publishing the engineering and the economics. I am not publishing the corpus, the solver, or anything resembling a recipe. The underlying datasets are publicly licensed research sets, used here for research, and that is where the openness ends. The point is not to defeat a gate. The point is what these numbers teach about building AI systems that are cheap, fast, and yours to keep. Filho feio nao tem pai, we say in Brazil. An ugly child has no father. I am not going to father a tool for the wrong hands, so I am keeping the parts that would build one to myself.
And one boundary matters more than all the rest. Every bit of development and testing in this study ran against Google’s own official reCAPTCHA test endpoint, and nothing else. No third party’s website, no production system, no live protection was ever touched, probed, or bypassed. This was a recognition experiment run on the vendor’s own test bench, not an attack on anyone’s gate.
The recipe, for its part, is not a secret I am hoarding. It is a door, and I am choosing who walks through it. If you are a researcher who wants to peer-review this work properly, get in touch directly and I will walk you through the methodology in full. Serious scrutiny is exactly what good work invites. A turnkey kit for whoever wants to abuse it is not.
Three primitives, fast
If you already live in this world, skip ahead. If you don’t, here is the whole vocabulary you need, in plain terms.
RAG. Retrieval-augmented generation. Most people meet it as text: a chatbot bolted onto your company documents, answering from them instead of from whatever it absorbed in training. The trick underneath is simple. You turn each piece of reference material into a vector, a long list of numbers that captures its meaning, and you store all those vectors. At question time you look up the nearest ones instead of asking a model to reason from a blank page. RAG is the difference between memorizing the library and carrying a library card. The knowledge lives in the index, not in the weights, which means you can add to it on a Tuesday afternoon without retraining anything.
Visual RAG is the same move with pixels. Embed every reference image into a vector, store them, and when a new image shows up, ask which known images it sits closest to. The answer comes back as a neighborhood, not a guess. The fingerprints here come from DINOv3, Meta’s self-supervised vision model, which learned to see without anyone handing it a single label, and the whole system is only ever as good as those fingerprints.
VLM. A vision-language model. The world met AI through a chatbot: type words, get words. A VLM is that same transformer machinery pointed at images. Show it a picture, ask a question in natural language, and it reasons over what it sees. The strength is flexibility. It is open-vocabulary, so you can ask for “a fire hydrant partly hidden behind a parked car” and it will take a real swing at it, even though no one ever trained it on that exact phrase. That flexibility is genuine, and it is why people reach for VLMs. It is also why they are slow. Every single query reasons from the raw pixels up. A VLM looks. The chatbot you already know talks. Same family, different sense organ. They show up in document understanding, accessibility tools that narrate the world for blind users, medical imaging triage, robotics, content moderation, visual search. Real applications, not toys.
YOLO and LocateAnything. Two more tools, and both earned their place. YOLO, now in its YOLO26 generation from Ultralytics, is the workhorse real-time detector that has been the model to beat on COCO for years, and it is genuinely excellent at what it does. I am deliberately not quoting its benchmark numbers, because that is the apples-to-oranges trap again: YOLO is locked to the fixed categories it was trained on, so it has nothing to say about the open-vocabulary scene classes, and setting its COCO score beside anything in this piece would line up two different jobs and call it a race. In this system it is something more useful than a leaderboard line anyway, a phenomenal gated fallback, the fast and certain hand the cascade reaches for when a tile sits squarely in its wheelhouse. LocateAnything-3B is the open-vocabulary half, and the one I actually benchmarked against. It is NVIDIA’s grounding model, a 3-billion-parameter vision-language system that localizes objects from a plain-language description. I want to be fair to it, because fairness is the entire point of a benchmark. It is genuinely good, and it is not even slow by VLM standards: its headline trick, parallel box decoding, was built specifically to make grounding fast, roughly two and a half times faster than the grounding models that came before it. It handles the awkward scene classes a fixed detector has no word for, and it was the strong opponent in this fight, not a strawman propped up to lose. That is exactly why beating it on accuracy at 180 times the speed means something. You do not get a number like that against a weak model.
The architecture nobody draws
Here is the move almost everyone misses. They take the most expensive model in the building and wire it to one hundred percent of the traffic.
The engineered version is a cascade. Cheap retrieval answers first. When the nearest-neighbor vote is decisive, and on a clean corpus it usually is, you are done in under a millisecond. Only when retrieval comes back uncertain, that murky middle where the neighbors disagree, do you escalate. The detector or the VLM gets called in for the genuinely hard tile, and nothing else. The expensive model never even sees the easy ninety percent.
This inverts how most teams build. The VLM is not the system. It is the fallback. The system is a fast, accurate layer that knows when it is out of its depth, sitting in front of a slow, expensive layer that only ever gets the questions worth its time.
Think about how a veteran operator actually works. You hand a senior tech a thermal trace, or an oscilloscope capture, or a single tile of a street scene, and they just know. Not because they re-derive it from Ohm’s law or recompute it from the raw photons hitting the sensor. Because they have seen ten thousand of them and this one matches something already in their head. Recognition is a lookup. The brilliant newcomer, fresh and slow, reasons every case out from first principles, arrives at the right answer, and bills you for the hour it took to get there. The veteran glances and moves on. A vision-language model is the brilliant newcomer. Retrieval is the veteran. Both are right most of the time. Only one of them is right in seven-tenths of a millisecond, and only one of them gets cheaper and faster the more it has already seen.
Which raises the only question that matters. How do you build the veteran’s eye?
You distill it
The first corpus I built was bigger and worse. 46,875 tiles, scraped together from everything I could find, and it scored a k-NN purity of 0.812 with poor cluster separation. The version running now is smaller, 27,497 tiles, and it scores 0.921 purity and 0.960 top-1 accuracy, with cluster separation up better than half from where it started. I removed roughly forty percent of the data and the thing got sharper.
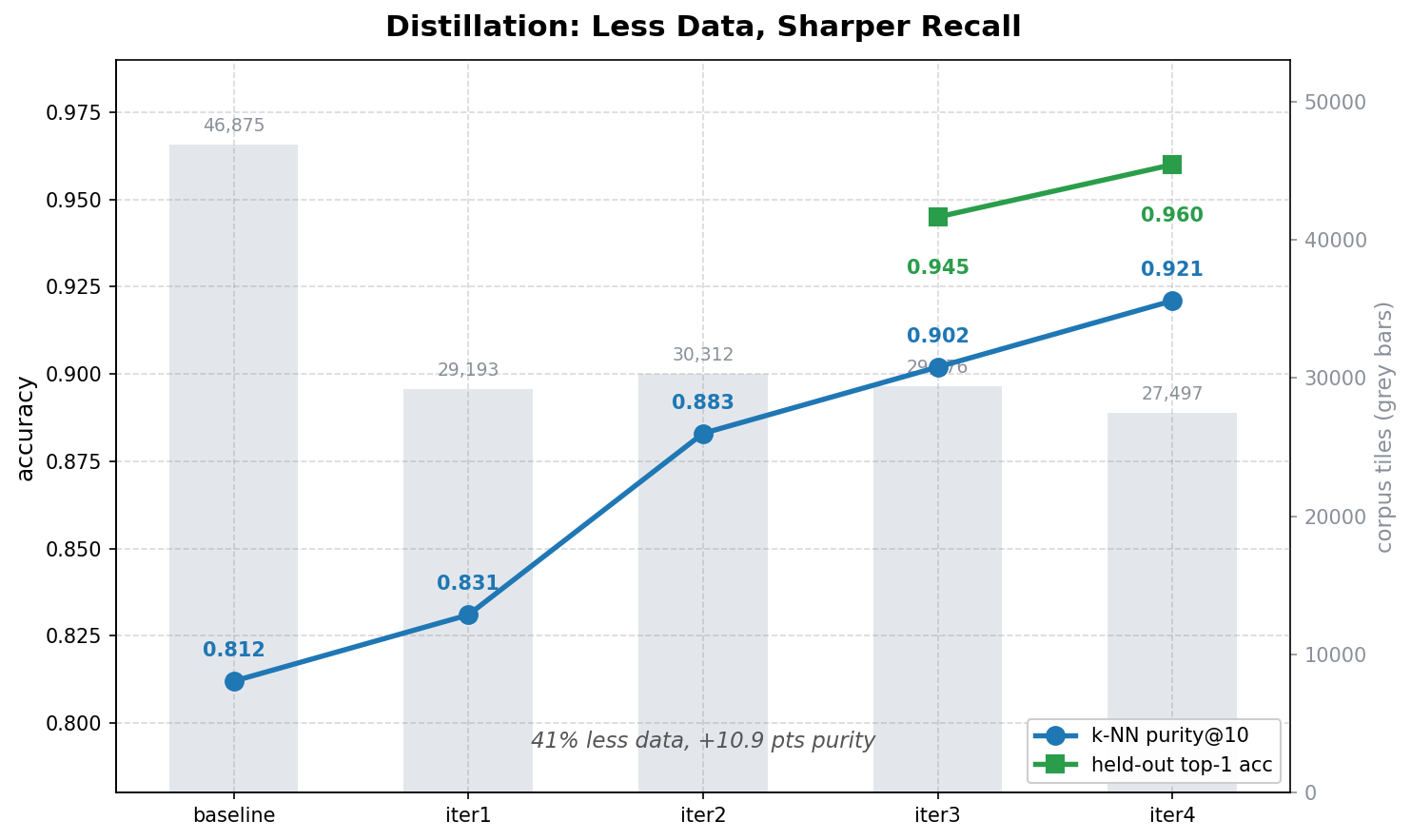
Five rounds of curation. The corpus shrinks at the steps that matter, and every quality line climbs.
That is the whole article in two sentences. Bigger is not better. Curated is better. Here is what curation actually meant, because every step left a mark.
Fake diversity. My first corpus pulled from two sources I was proud of, right up until I measured them and found they were sixty-three percent the same images. I had paid for two and gotten one. Diversity has to be genuinely independent to count for anything. Two copies of the same bias is just the same bias, louder.
Near-duplicates are eval poison. Exact-match dedup is not enough. My first pass removed only byte-identical and pixel-identical files, and a swarm of near-duplicates survived, images a few bits apart. The mountain category was the tell: 1,508 tiles collapsed to 24 the moment I started collapsing near-duplicates properly, because the source was something like ninety-eight percent the same handful of photographs. Those 1,484 tiles were not data. They were one exam question photocopied 1,484 times. A model trained and tested on that looks brilliant right up until it meets a mountain it has not already memorized, and then it falls on its face.
Label noise. One of my classes was a catch-all called “other.” Its purity was 0.04. That is not a category, it is a junk drawer, and I threw it out.
Let AI grade AI’s homework. I used three models as automated reviewers of my own training data: a YOLO detector, a segmentation model, and LocateAnything itself. Where the detector looked at a tile and saw no such object, I quarantined it: 4,225 tiles gone. Where a vehicle sat marooned in a sea of background, I recropped it tight to the silhouette: 7,362 tiles fixed. And for the open-vocabulary scene classes a fixed detector has no word for, the crosswalks and chimneys and bridges, LocateAnything was the judge that could actually ground them, a yes-or-no on whether the thing was really in the frame. This is the AI-gate, and it is one of the most useful patterns I know. Models make cheap, patient, tireless reviewers of the data that trains other models.
Then let a human grade the AI. The gates are not enough on their own. There is a review console, a human in the loop, looking at the hard captures next to their corpus neighbors and deciding: real fire hydrant, or not. A hundred and twenty-two of those human verdicts went back into the corpus. That is the apprenticeship. The machine proposes, the operator disposes, and the judgment that comes out the other end is the part no model was ever going to hand you for free.
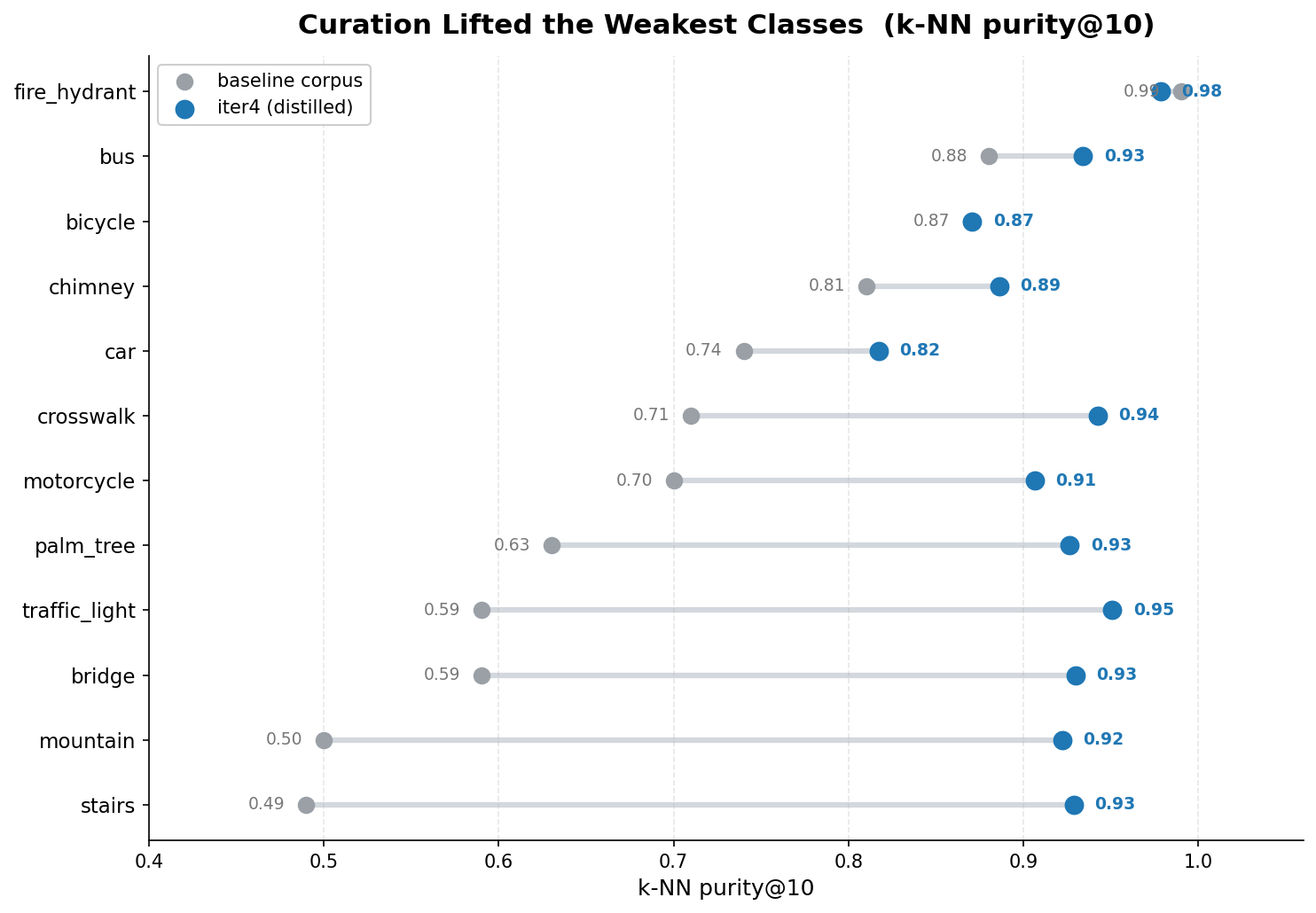
The categories that were drowning came up the most. car barely moved, and it is still the floor. Hold that thought.
Not every lesson was flattering. When I added clean, correct, independent street photography to the car category, its purity dropped, from 0.74 down to 0.56. More correct data made the number worse. The reason is real and a little humbling: cars and trucks and buses are visually nested, the same way a sedan and a pickup share a silhouette at a glance, and an appearance-based index files them as neighbors because at the level of raw pixels that is exactly what they are. I left the regression in the written record instead of quietly deleting the data that caused it. Evidence over comfort. The number that embarrasses you is usually the one worth keeping.
The fix, when it came, was not more data. It was less. Trucks are not even a reCAPTCHA challenge category. The only reason they were in my corpus at all was to fill a class that looked empty, and they turned out to be the single worst thing confusing my cars. A class I added for coverage was actively hurting a class that mattered. So I dropped it, car purity jumped to 0.81, and the aggregate top-1 climbed to 0.960. The corpus has to match the question you are actually asking, not the question you imagined you might ask someday.
At one point, deep in the pruning, I stopped and asked myself the only question that keeps this kind of work honest. Is this real, or am I just gaming my own benchmark? It is a fair worry, because you can always make a test score go up by quietly making the test easier, and a person motivated to see a number climb will find a way to climb it. My answer, written down at the time so I could not weasel out of it later: the gains were proportionate to the cuts rather than suspicious little jumps from tiny edits, the tiles I removed were defensible errors like a “car” crop whose only detectable vehicle was a truck, and the caveat got recorded in plain language, that a cleaner test set is also an easier one and some of the lift is that, not pure skill. You do not get to claim a number you would be embarrassed to defend in front of someone who knows better.
End state: 27,497 tiles. 114 megabytes of embeddings. It beats the 3B VLM on accuracy and it does it 180 times faster.
One more thing, because I am asking you to trust a number. I did not take that 0.921 purity on faith from the same tooling that produced it. I reloaded the raw embeddings and recomputed the aggregate from scratch, on a separate code path, and got 0.921 again. The same number, reached twice, by two routes. That is the only kind of number worth putting on a chart.
And here is the part I find genuinely elegant, the part that deserves a tip of the hat. The model I beat is the model that helped me build the thing that beat it. LocateAnything did the open-vocabulary grounding that surfaced the hard positives, the tiles my retrieval layer was quietly missing, so a human could confirm them and feed them back into the corpus. Every turn of that loop added a little curated, incremental knowledge to the index and made it sharper and more independent of the VLM that seeded it. The expensive model taught the cheap one, then stepped back to being the fallback for the handful of cases the cheap one still cannot handle on its own. That is not a defeat for LocateAnything. It is what a good teacher does. Real credit to the NVIDIA team that built it; a fast, honest grounding model is what made this distillation possible in the first place.
What a clean corpus looks like
Every one of those 27,497 tiles is a point in a 1,024-dimensional space, which is not a thing a human can look at. So here is that space crushed down to two dimensions, each point colored by its category. It is the closest you can get to seeing what the retrieval layer sees when it goes looking for neighbors.
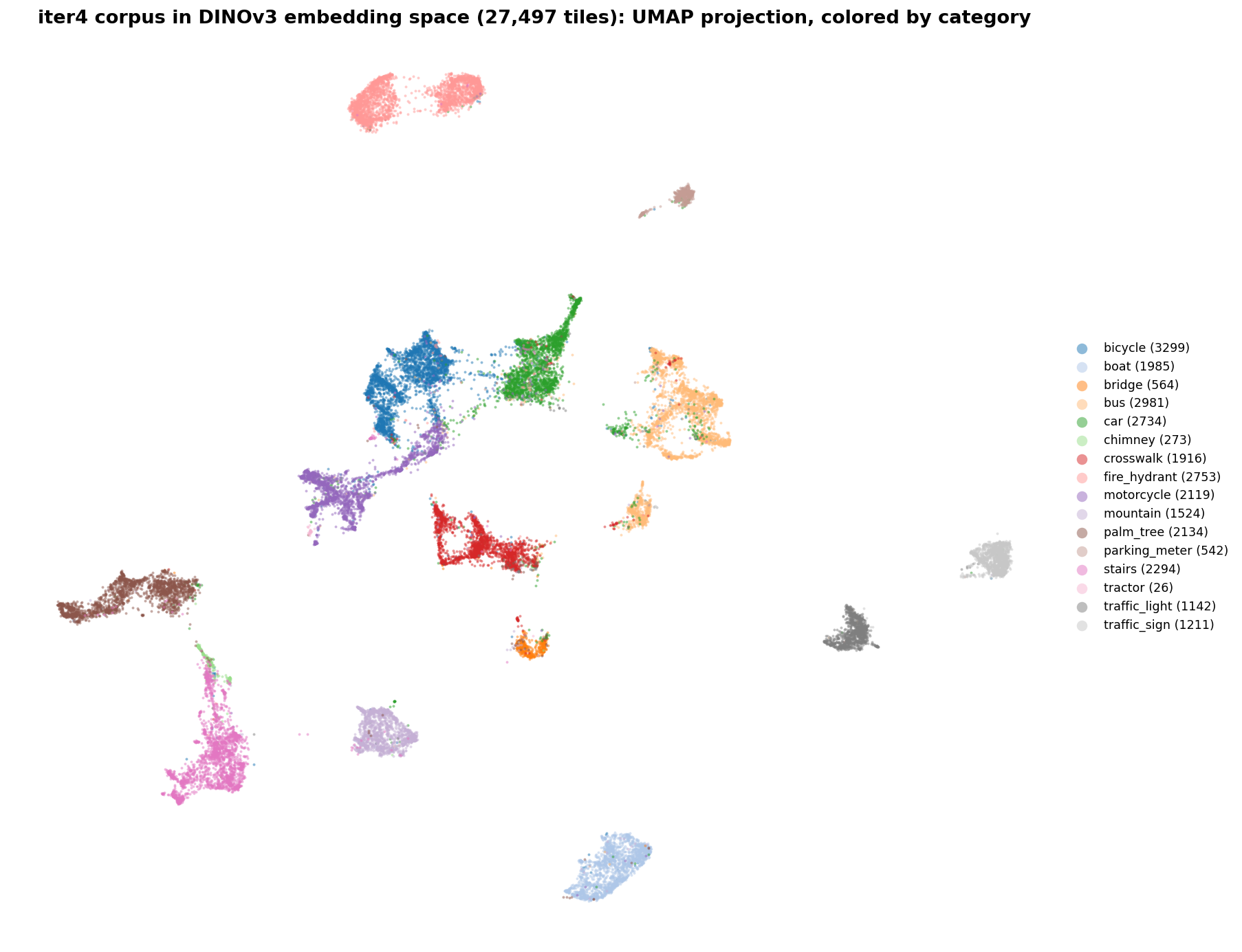
The corpus, flattened to two dimensions. Clean categories pull apart into their own islands. Look at the vehicles, though: car, bus, bicycle, and motorcycle pile into one crowded neighborhood, because at the level of raw appearance that is exactly what they are. That crowd is the car number you saw a minute ago.
A clean island is a class the retrieval layer will nail. A smeared, overlapping blob is a class it will sometimes miss, and no amount of squinting at the picture changes the fact underneath it: things that look alike land near each other. This map is not a marketing diagram. It is the territory the nearest-neighbor search actually walks at query time.
The right tool for the right problem
Let me be honest about what this is, because the headline number invites a misread. COCO, the standard object-detection benchmark, covers eighty categories. A frontier vision-language model is open-vocabulary, so it will gamely take a swing at effectively anything you can name, in a phrase it has never been trained on. This corpus covers sixteen. It is not a general vision system and it is not pretending to be one. Show it a category it has never been given and it has nothing useful to say, and that is fine.
The narrowness is not the hole in the argument. It is the argument. The whole deployable footprint is under a hundred and fifty megabytes. It fits in RAM with room to spare, it answers in under a millisecond, and it does it on a CPU. You are not renting a frontier model’s general intelligence to decide whether a tile holds a fire hydrant. You built a small, sharp instrument that does that one job, kept it, and it runs blazing fast on hardware you already own.
Under a hundred and fifty megabytes is small enough to live on a phone. The thing it replaces, a frontier model reached through an API to answer the same small question, runs in a data center that costs millions to build and megawatts to keep cool. Same answer. One version fits in your pocket. The other needs its own substation.
A frontier VLM is a thousand-blade knife, and you pay to carry every blade each time you reach for the one. This is the one blade, honed. Right tool, right problem. That is the whole discipline: know which problem you actually have, and stop paying for the problems you do not.
The benchmarks still on the bench
I am not going to fabricate numbers I have not finished measuring. Three more studies are coming, and here is exactly what each one tests, so the methodology is on the table before the results are.
Standard RAG versus cuVS. The same sub-150-megabyte index searched two ways: the standard path, on a CPU with the vectors held in RAM, against NVIDIA’s cuVS on the GPU. At this size the interesting question is not whether the GPU can win a raw race, it can, but whether it ever needs to, and what each path actually costs in latency and watts when the whole index already fits in memory. (Coming.)
Wall time for a real challenge. Not a synthetic tile in a notebook. The end-to-end clock on an actual escalated challenge in punish mode, where the gatekeeper demands nine or more rounds before it relents, scored per round rather than only on the rare clean sweep everyone likes to quote. Aggregate timing and methodology only, nothing about orchestration. (Coming.)
The cost of wiring it to an API. What the same job costs when you hand it to a frontier pay-as-you-go model instead: the price of the first pass, the price of the tenth pass, and the honest long-term number, the running cost of resolving a recurring problem through someone else’s API meter forever, against resolving it once, here, on an index you own. That last figure is the whole argument as a single line item. (Coming.)
Owned knowledge versus rented knowledge
Now the economics, which is where this stops being a lab curiosity and becomes a line on a budget.
The distilled corpus is a capital asset. I built it once. It is a hundred and fourteen megabytes. It answers in under a millisecond, on a CPU if I feel like it, and it will answer the same way next year, because the knowledge is sitting in an index I own, not borrowed from a context window that is about to close. I can copy it, version it, audit it, and hand it to a colleague.
The wire-an-AI approach is an operating expense that never stops. Every challenge is a fresh invoice: tokens in, GPU cycles burned, minutes of wall clock, and an answer the company pays for and does not get to keep. The next challenge looks brand new to the model even when it is identical to one solved an hour ago, so you pay again, for knowledge you already bought once. That is not a pipeline. It is a meter running. The knowledge evaporates the instant the context window scrolls, which is the same failure I described as context drift, the slow leak that kills agents long before latency does.
I have made a version of this argument in dollars before, when one rented GPU did a job for seventy dollars that the frontier APIs wanted twenty thousand to run. This is the same argument in milliseconds and megabytes. And underneath both is the point I keep landing on: applied AI is augmentation, not replacement. The human in the loop who decided which tile held a real fire hydrant was never optional. The model proposed. The operator disposed. The corpus remembers.
You do not need a vision model to see. You need to have looked, once, carefully, and kept what you saw. Real engineering compounds. Brute force just rents.
Credits and references. The retrieval index is built on DINOv3, Meta AI’s self-supervised vision backbone (Simeoni et al., “DINOv3,” arXiv:2508.10104, 2025). The vision-language baseline and grounding judge is NVIDIA’s LocateAnything-3B (Shihao Wang, Shilong Liu, Yuanguo Kuang, Xinyu Wei, Yangzhou Liu, Zhiqi Li, Yunze Man, Guo Chen, Andrew Tao, Guilin Liu, Jan Kautz, Lei Zhang, and Zhiding Yu, “LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding,” arXiv:2605.27365, 2026; model card, project page). The COCO-class detector and gated fallback is YOLO26 from Ultralytics. Credit to all three teams; this work stands on their shoulders.